llama.cpp ist eine Open-Source-Softwarebibliothek, die größtenteils in C++ geschrieben ist und Inferenzen auf verschiedenen Large Language Models wie Llama durchführt. Ein CLI und ein Webserver sind in der Bibliothek enthalten. llama.cpp wurde zusammen mit dem GGML-Projekt entwickelt, einer allgemeinen Tensor-Bibliothek.
Das Modell Phi3 verwendet eine Kombination aus quantitativen und qualitativen Methoden, um eine umfassende Risikobewertung zu ermöglichen. Dabei werden sowohl finanzielle als auch nicht-finanzielle Aspekte berücksichtigt.
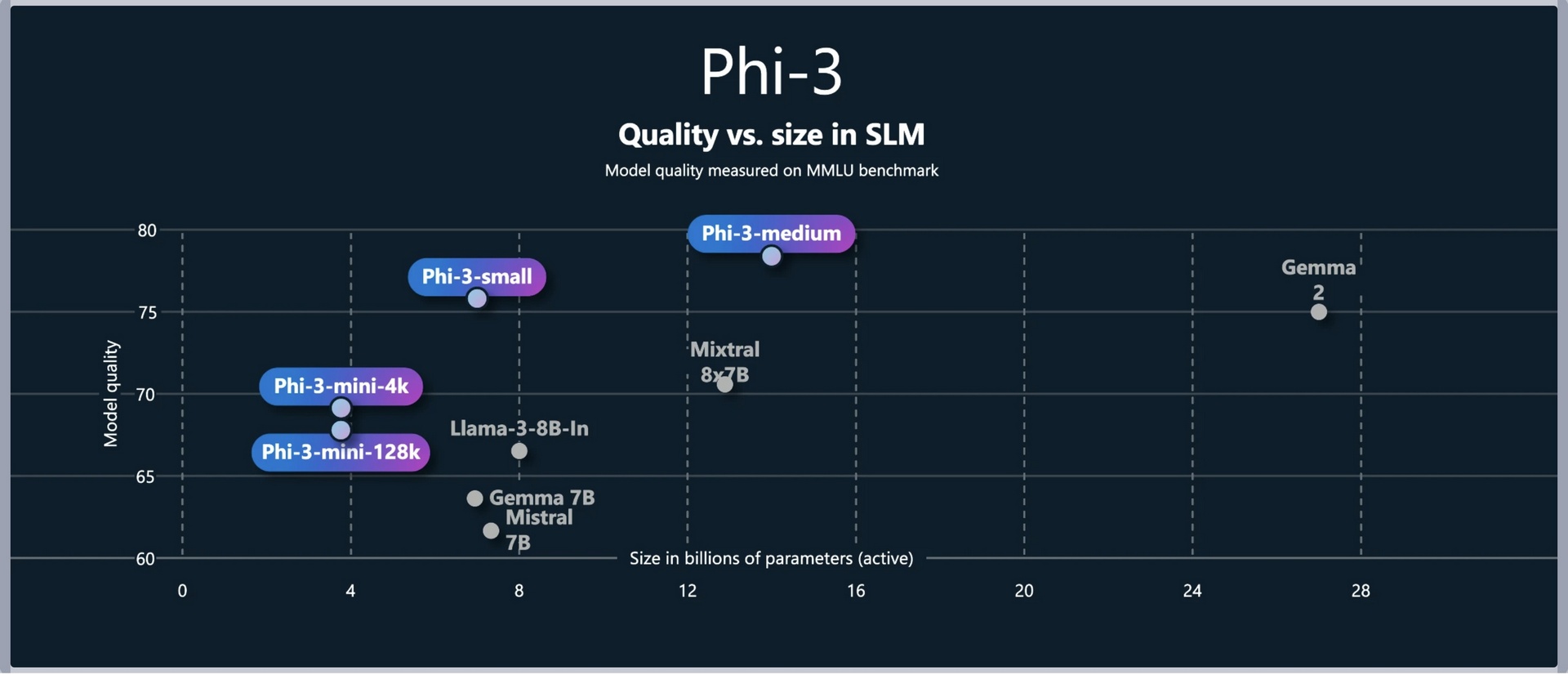
The Phi-3-small model, with only 7B parameters, has demonstrated superior performance over GPT-3.5T across various language, reasoning, coding, and...
Phi-3-small achieves superiority.
llama.cpp wurde entwickelt, um große Sprachmodelle effizient auf CPUs auszuführen, ohne GPUs zu benötigen.

Das macht es zu einer leichten und portierbaren Alternative zu Frameworks, die GPUs erfordern.
Es verwendet Quantisierung, um Speicheranforderungen und Rechenleistung zu reduzieren.

Gewichte des Modells werden in weniger präzise Datenformate umgewandelt.
llama.cpp bietet volleKontrolle und höhere Datensicherheit. Die einmaligen Kosten machen es anpassbar und offline nutzbar, aber es erfordert hohe Hardwareanforderungen und manuelle Updates.

Im Vergleich dazu benötigt ChatGPT keine Hardware, ist einfach skalierbar und bietet automatische Updates. Es ist leistungsstark und sofort verfügbar, hat jedoch Datenschutzrisiken und laufende Kosten.

Insgesamt ist llama.cpp ideal für Datenschutz und Kontrolle, während ChatGPT praktisch und leicht zugänglich ist, aber datenabhängig und kostenintensiv. Jedes hat seine eigenen Vor- und Nachteile.

llama.cpp bietet volle Kontrolle und höhere Datensicherheit
Niedrigere Betriebskosten: Reduzieren Sie laufende Kosten durch den Einsatz vorhandener Infrastruktur.

Volle Datenkontrolle: Verwalten Sie KI-Modelle intern, um sensible Daten nicht an externe Cloud-Dienste zu senden.

Compliance sicherstellen: Erfüllen Sie Datenschutzbestimmungen, indem Sie Daten innerhalb Ihres eigenen Netzwerks verarbeiten.

Kosteneffizient arbeiten: Keine teure Hardware nötig - llama.cpp ermöglicht den Betrieb auf CPU-basierten Servern. wodurch Investitionen in GPUs entfallen.

Reduzieren Sie laufende Kosten durch den Einsatz vorhandener Infrastruktur
Unsere Aufgabe wird durch die Nutzung einer On-Premise-Lösung und der ChatGPT-Cloud gelöst. Diese Kombination ermöglicht eine effiziente und maßgeschneiderte Lösung für unsere Anforderungen.
Wir möchten demonstrieren, wie man mit llama.cpp eine Känguru Mathematik Aufgabe 11-13 Klasse lösen kann.
Wir haben dazu einen Docker-Container auf On-Premise Basis aufgebaut. Wir zeigen hier, wie man eine Infrastruktur aufbauen kann.
Die Mathematik-Aufgabe aus Känguru 2024 ist für die Klassenstufen 11 bis 13 konzipiert und bietet anspruchsvolle Herausforderungen für Schülerinnen und Schüler in diesen Jahrgangsstufen.
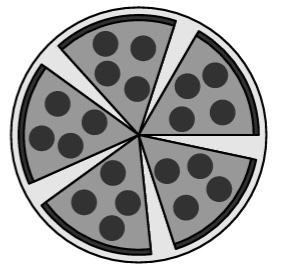
Mattis hat eine Pizza in sechs gleich große Stücke geschnitten. Nachdem er ein Stück gegessen hat, ordnet er die restlichen Stücke so an, dass die Lücken zwischen benachbarten Stücken alle gleich groß sind. Wie groß ist jeweils der Winkel, den zwei benachbarte Stücke einschließen?
Mit der steigenden Nachfrage nach leistungsfähigen Sprachmodellen suchen viele Unternehmen nach Möglichkeiten, diese sicher und effizient on-premise zu betreiben. llama.cpp bietet eine Open-Source-Lösung für die Ausführung von großen Sprachmodellen auf eigener Hardware. In diesem Artikel erfahren Sie, wie Sie llama.cpp unter Docker betreiben können, um maximale Datensicherheit zu gewährleisten, und welche Alternativen es gibt.

Die Hardware-Infrastruktur erfordert eine CPU-Architektur von x86_64 oder ARM mit AVX2-Unterstützung für bessere Leistung. Es werden mindestens 4 Kerne empfohlen, 8 oder mehr für eine verbesserte Leistung.
Der Arbeitsspeicher sollte mindestens 8GB RAM betragen, idealerweise 16GB oder mehr. Es wird empfohlen, dass der RAM mindestens doppelt so groß ist wie das zu ladende Modell.
Für eine optimale Leistung ist eine NVIDIA-GPU mit CUDA-Unterstützung erforderlich. Die GPU sollte mindestens 8GB VRAM für größere Modelle und eine neuere RTX 20xx oder höher aufweisen.
Link vom Modell, proejkt seite
update

Managing Consultant

Security Advisor